
Всё ещё пользуетесь GridSearchCV? Тогда мы идём к вам!
В последнее время замечаю, что народ соскакивает с проверенного временем метода подбора параметров моделей при помощи GridSearchCV из модуля model_selection библиотеки scikit-learn на библиотеку optuna.
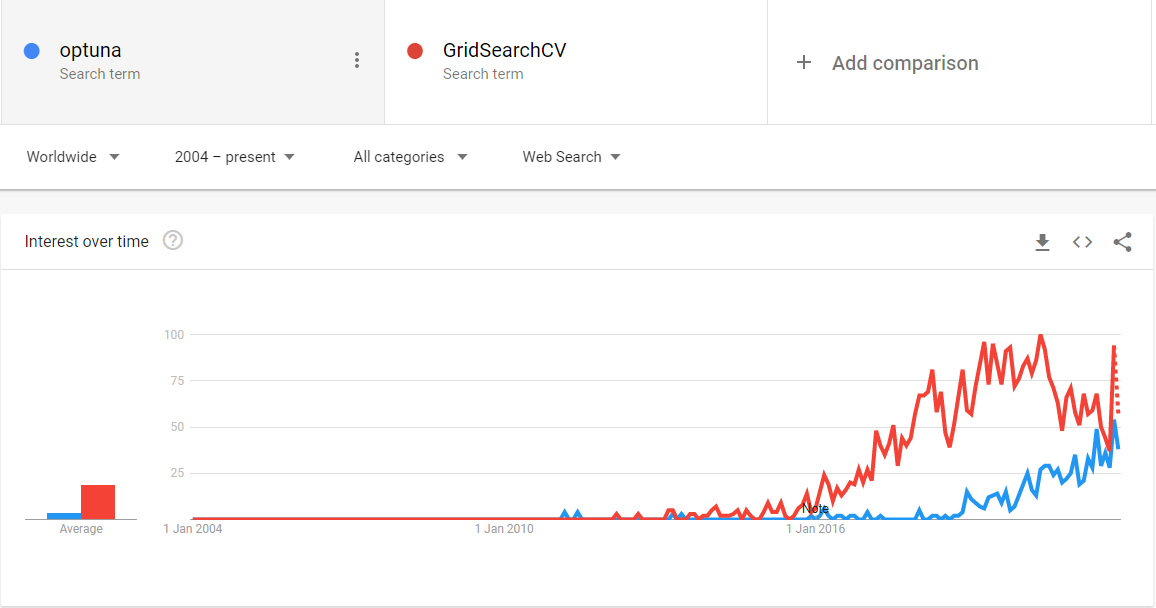
Судя по Google Trends эта волна началась около трёх лет назад, но я узнал про библиотеку лишь несколько месяцев назад и успел применить только в паре соревнований.
В optuna есть три основных понятия:
trial— один запуск функции, качество которой оптимизируем,study— сессия оптимизации. Состоит из несколькихtrial,parameter— подбираемый параметр для оптимизации функции. В примере ниже это, например,objectiveилиcolsample_bylevel.
Пример использования optuna для поиска оптимальных параметров в задаче классификации при помощи CatBoostClassifier:
import optuna
from catboost import CatBoostClassifier
from sklearn.metrics import roc_auc_score
import pandas as pd
def run_cb(trial):
param = {
"objective": trial.suggest_categorical("objective", ["Logloss", "CrossEntropy"]),
"colsample_bylevel": trial.suggest_float("colsample_bylevel", 0.01, 0.1),
"depth": trial.suggest_int("depth", 1, 12),
"boosting_type": trial.suggest_categorical("boosting_type", ["Ordered", "Plain"]),
"bootstrap_type": trial.suggest_categorical(
"bootstrap_type", ["Bayesian", "Bernoulli", "MVS"]
),
}
if param["bootstrap_type"] == "Bayesian":
param["bagging_temperature"] = trial.suggest_float("bagging_temperature", 0, 10)
elif param["bootstrap_type"] == "Bernoulli":
param["subsample"] = trial.suggest_float("subsample", 0.1, 1)
cb_model = CatBoostClassifier(**param)
train_cols = [x for x in train if x != 'target']
cb_model.fit(
train[train_cols],
train['target'],
early_stopping_rounds=100,
eval_set=[(, )],
verbose=1000)
preds = cb_model.predict_proba(test[train_cols])[:, 1]
score = roc_auc_score(test['target'], preds)
return score
def read_data(path: str) -> pd.DataFrame:
if path.endswith('csv'):
df = pd.read_csv(path)
elif path.endswith('pkl'):
df = pd.read_pickle(path)
else:
raise ValueError(f'Unkonwn file extension {path}')
return df
if __name__ == '__main__':
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')
cb_study = optuna.create_study(direction="maximize")
cb_study.optimize(run_cb, n_trials=100, timeout=60)
Далее кратко опишу, почему я перешёл на optuna вместо привычного GridSearchCV.
Удобное формирование сетки параметров
Для создания сетки параметров используются методы класса Trail. Например,
suggest_categorical(name, choices)— для категориальных значений. Например,bootstrap_typeвCatBoostClassifier.suggest_float(name, low, high, *[, step, log])— для вещественных параметров. Например,subsampleвCatBoostClassifier.suggest_int(name, low, high[, step, log])— для целочисленных параметров. Например,depthвCatBoostClassifier.
Другие варианты можно посмотреть в документации.
Кроме тогол, у меня неоднократно возникала проблема с GridSearchCV когда не все комбинации параматров работают друг с другом. В API optuna есть возможность в run-time задавать параметры для текущего trial в зависимости от значений других параметров:
if param["bootstrap_type"] == "Bayesian":
param["bagging_temperature"] = trial.suggest_float("bagging_temperature", 0, 10)
elif param["bootstrap_type"] == "Bernoulli":
param["subsample"] = trial.suggest_float("subsample", 0.1, 1)
Возможность задавать количество “попыток” для подбора параметров
В отличие от GridSearchCV, который перебирает все возможные комбинации и, соотвественно, количество вариантов будет равно произведению количеств каждого параметра, optuna можно задать количество trial-ов. Каким образом выбирать параметры библиотека решает самостоятельно. Утверждают, что алгоритм использует какие-то SOTA решения:
# Проверим 100 различных комбинаций параметров.
cb_study.optimize(run_cb, n_trials=100)
Возможность задать таймаут для подбора параметров
Кроме того, чтобы указать количество trial-ов, можно указать какое время библиотека может перебирать параметры (в минутах):
# Перебираем параметры в течение часа.
cb_study.optimize(run_cb, timeout=60)
Единый API для разных библиотек машинного обучения
Помимо вышеперечисленного optuna можно использовать с разными библиотеками для ML: я его использовал с LightGBM, XGBoost, CatBoost и разными алгоритмами из scikit-learn.
Стоит упомянуть
Возможности optuna, которые афишируются, но пока не использовались мной на практике:
- Визуализация процесса подбора и важности гиперпараметров
- Multi-objective подбор гиперпараметров: одним study можно оптимизировать несколько метрик
- Продолжение подбора параметров после завершения одной “сессии” подбора параметров
optunaподдерживает работу на GPU