
Сколько страниц книги необходимо прочитать, чтобы узнать 90% всех слов?
Вдохновившись статьёй для английских книг, решил проверсти аналогичный анализ для русских произведений.
Преподаватель английского языка автора оригинальной статьи утверждал, что прочитав 20 страниц любой книги можно узнать 90% всех слов произведения и далее читать книгу будет значительно проще.
В этой статье я хочу проверить аналогичное утверждение для русского языка: сколько страниц необходимо прочитать, чтобы узнать 90% книги.
Спойлер: прочитав 20 страниц книги вы практически наверняка не узнаете 90% всех слов. Далее будут графики, таблицы и немного кода.
Для анализа требуется стандартный для подобных задач набор бибилиотек Python: matplotlib, seaborn, pandas, numpy, stop_words и pymorphy2.
Что анализировать?
В качестве “подопытных” взял различные книги:
- Объёмную классику (Л. Толстой “Война и мир. Книга 1.")
- Нехудожественная литература (С. Галёнкин “Маркетинг игр”)
- Случайную бесплатную современную книгу на litres (С. Тармашев “Закат Тьмы”)
- Книгу, переведённую на русский (Ш. Стрейд “Дикая”)
- Небольшой рассказ Антона Чехова (А. Чехов “Человек в футляре”)
Что хотим узнать?
- Как быстро появляются новые слова в книге?
- Какой процент книги можно прочитать зная слова, которые были встречены к некоторой странице?
На графиках к книгам зелёный линия даёт ответ на первый вопрос: какой процент всех уникальных слов в книге были встречены к текущей странице. Синяя линия на графике отвечает на второй вопрос: какой объём от всей книги написан при помощи слов встреченных к текущей странице.
from matplotlib import pyplot
import seaborn as sns
from collections import Counter
from itertools import chain
import pandas as pd
import numpy as np
import re
import pymorphy2
from stop_words import get_stop_words
page_size = 200
Подготовка данных
Для подготовки книг в виде текстовых файлов для анализа используем pymorhy2 для лемматизации и stop_words для удаления стоп-слов:
morph = pymorphy2.MorphAnalyzer()
sw = get_stop_words('ru')
pyplot.rcParams["figure.figsize"] = (10,5)
def lemmatize(text):
"""Функция удаляет из текста стоп-слова,
лемматизирует текст и берёт для каждого начальную форму.
# Arguments
text: исходный текст.
# Returns
fixed_text: список лемматизированых не-стоп-слов.
"""
letters_only = re.sub('[^a-zA-Zа-яА-Я]', ' ', text)
fixed_text = []
letters_only = list(filter(None, letters_only.split(' ')))
for word in letters_only:
# Берём первое совпадения только для простоты.
nf = morph.parse(word)[0].normal_form
if nf in sw:
continue
fixed_text.append(nf)
return fixed_text
def txt_to_pages(filename, encoding='utf8'):
"""Функция преобразует текст из текстового файла в "страницы"
# Arguments
filename: путь до текстового файла.
encoding: кодировка исходного файла.
# Returns
book_pages: список списков лемматизированных слов ("страниц")
"""
book_text = open(filename, mode='r', encoding=encoding).read()
book_text = lemmatize(book_text)
book_pages = []
for i in range(len(book_text) // page_size + 1):
book_pages.append(book_text[i * page_size : i * page_size + page_size])
return book_pages
Обработка книг
Следующие две функции содержат всю логику по анализу книг:
- вычисляют “сложность” книги - сколько страниц текста необходимо прочитать, чтобы узнать 90% всех уникальных слов,
- вычисляют основные метрики книги - какой процент книги возможно прочитать зная слова встреченные к текущей странице, какой процент уникальных слов уже встречен.
def calculate_hardness(coverage, percent = 0.9):
""" Функция вычисляет "сложность" книги -
насколько большую часть книги необходимо прочтитать,
чтобы узнать percent всех используемых слов.
# Arguments
coverage: массив с информацией какой процент книги
можем прочитать, зная слова полученные к i-ой странице.
percent: сколько слов хотим знать.
# Returns
i: номер страницы.
hardness: какой процент книги будет прочитан к этой странице.
"""
for i in range(len(coverage)):
if coverage[i] > percent:
break
hardness = (100 * i) / float(len(coverage))
return i, hardness
def percentage(values, title):
""" Функция вычисляет всё.
# Arguments
values: список "страниц" книги.
"""
all_words = list(chain.from_iterable(values))
result = {}
current_text = []
page_counter = 0
file_name = title.lower().replace(' ', '_').replace('\'','') + '.png'
counter = Counter()
# "Счётчик" всех слов книги.
# Используется для подсчёта процента книги,
# который можно прочитать зная некоторый объём слов.
occurances = Counter(all_words)
# i-ый элемент: какой процент книги можем прочитать зная слова полученные к i-ой странице.
coverage = []
# i-ый элемент: какой процент слов используемых в книге знаем к i-ой странице.
uniqueness = []
# i-ый элемент: сколько уникальных слов используемых в книге знаем к i-ой странице.
total_unique_words_count = []
total = float(len(all_words))
total_unique = float(len(occurances.keys()))
print('page\ttotal\tpercent of all\tpercent of book\tuniqueness')
for page_text in values:
# Обновим счётчик уникальных слов словами с новой страницы.
counter.update(page_text)
# Посчитаем, сколько вообще раз встречаются слова
# которые уже были встречены к текущей странице.
occured_words_count = sum((occurances[w] for w in counter.keys()))
# Какой процент от всей книги составляют слова,
# которые уже встретили к текущей странице.
_coverage = occured_words_count / total
coverage.append(_coverage)
# Какой процент от всех уникальных слов встретили к текущей странице.
_uniqueness = len(counter.keys()) / total_unique
uniqueness.append(_uniqueness)
# Какой процент от книги прошли к текущей странице.
percent_book = page_counter / len(values)
# Сколько уникальных слов будет известно к текущей странице.
total_unique_words_count.append(len(counter.keys()))
print('{0}\t{1}\t{2:2f}\t{3:2f}\t{4:2f}'.format(page_counter,
len(counter.keys()),
_coverage,
percent_book,
_uniqueness))
result[page_counter] = {
'page': page_counter,
'unique_words': _uniqueness,
'all_words': _coverage
}
page_counter += 1
percent_df = pd.DataFrame.from_dict(result,orient='index')
page, hardness = calculate_hardness(coverage)
print('Всего страниц: {0}'.format(len(values)))
print('Всего слов: {}'.format(len(all_words)))
print('Всего уникальных слов: {}'.format(len(occurances.keys())))
print('Прочитав {0} страниц книги ({1:.2f}% всей книги) вы узнаете {2} уникальных слов.\n
К этой странице будут встречены 90% всех слов книги и {3:.2f}% уникальных.'.format(
page,
hardness,
total_unique_words_count[page],
uniqueness[page] * 100))
pyplot.plot(percent_df['unique_words'], color='g', label='Уникальные слова')
pyplot.plot(percent_df['all_words'], color='b', label='Все слова')
pyplot.legend(loc=4)
pyplot.title(title)
pyplot.xlabel('Страница')
pyplot.ylabel('Покрытие (%)')
pyplot.show()
Результаты
Л. Толстой “Война и мир. Книга 1”
war_and_peace_pages = txt_to_pages('./books/Tolstoyi_L._Voyinaimir1._Voyina_I_Mir_Kniga_1.txt',
encoding='1251')
percentage(war_and_peace_pages, 'Война и мир')
page total percent of all percent of book uniqueness
0 141 0.087556 0.000000 0.009748
1 286 0.158995 0.001541 0.019773
2 404 0.201158 0.003082 0.027931
3 521 0.238750 0.004622 0.036020
4 630 0.271941 0.006163 0.043556
5 732 0.306381 0.007704 0.050608
6 832 0.341545 0.009245 0.057522
7 923 0.360869 0.010786 0.063814
8 1007 0.387377 0.012327 0.069621
9 1096 0.404189 0.013867 0.075774
10 1179 0.417508 0.015408 0.081513
...
639 14463 0.999992 0.984592 0.999931
640 14463 0.999992 0.986133 0.999931
641 14463 0.999992 0.987673 0.999931
642 14463 0.999992 0.989214 0.999931
643 14463 0.999992 0.990755 0.999931
644 14463 0.999992 0.992296 0.999931
645 14463 0.999992 0.993837 0.999931
646 14463 0.999992 0.995378 0.999931
647 14463 0.999992 0.996918 0.999931
648 14464 1.000000 0.998459 1.000000
Всего страниц: 649
Всего слов: 129734
Всего уникальных слов: 14464
Прочитав 197 страниц книги (30.35% всей книги) вы узнаете 8171 уникальных слов.
К этой стрнице будут встречены 90% всех слов книги и 56.49% уникальных.
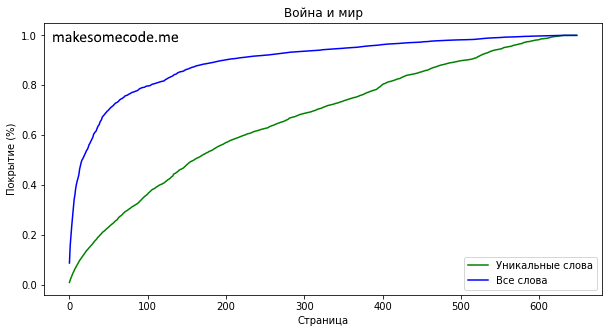
Книга “Война и мир. Книга 1." Льва Тостого содержит 649 страниц без учёта стоп-слов. На этих страницах можно встретить 14464 уникальных слов, каждое из которых, в среднем, встречается 9 раз. К 197-ой странице будет встречено 8171 уникальное слово (56.49% от всех уникальных слов). При помощи этих слов написано 90% всей книги.
С. Галёнкин “Маркетинг игр”
game_marketing_pages = txt_to_pages('./books/Games-Marketing-by-Galyonkin-v1.txt')
percentage(game_marketing_pages, 'Маркетинг игр')
page total percent of all percent of book uniqueness
0 145 0.250361 0.000000 0.044602
1 274 0.334958 0.017857 0.084282
2 392 0.386150 0.035714 0.120578
3 514 0.434543 0.053571 0.158105
4 614 0.481040 0.071429 0.188865
5 715 0.511015 0.089286 0.219932
6 798 0.545323 0.107143 0.245463
7 879 0.581347 0.125000 0.270378
8 955 0.617822 0.142857 0.293756
9 1042 0.646443 0.160714 0.320517
10 1108 0.668021 0.178571 0.340818
...
46 2938 0.964608 0.821429 0.903722
47 2973 0.968039 0.839286 0.914488
48 3015 0.972553 0.857143 0.927407
49 3057 0.979415 0.875000 0.940326
50 3094 0.983026 0.892857 0.951707
51 3131 0.987450 0.910714 0.963088
52 3167 0.990791 0.928571 0.974162
53 3187 0.992597 0.946429 0.980314
54 3242 0.999097 0.964286 0.997232
55 3251 1.000000 0.982143 1.000000
Всего страниц: 56
Всего слов: 11076
Всего уникальных слов: 3251
Прочитав 34 страниц книги (60.71% всей книги) вы узнаете 2485 уникальных слов.
К этой стрнице будут встречены 90% всех слов книги и 76.44% уникальных.
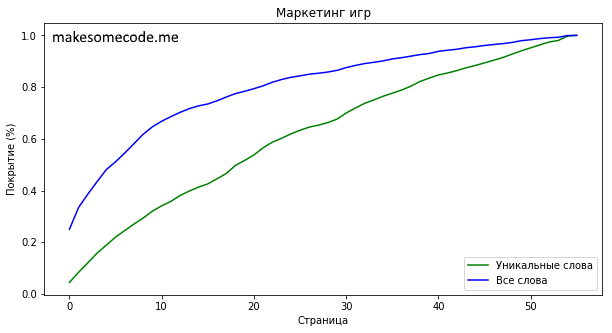
“Маркетинг игр” Сергея Галёнкина менее объёмная и содержит лишь 56 страниц текста. Уникальных слов в книге 3251. Для того, чтобы иметь возможность прочитать 90% книги необходимо знать 2485 уникальных слов (76.44% всех уникальных слов). Этого можно достичь к 34 странице.
С. Тармашев “Закат Тьмы”
zakat_tmyi = txt_to_pages('./books/Tarmashev_S._Tma3._Zakat_Tmyi.txt',
encoding='1251')
percentage(zakat_tmyi, 'Закат тьмы')
page total percent of all percent of book uniqueness
0 132 0.060600 0.000000 0.012445
1 251 0.073714 0.002611 0.023664
2 363 0.076843 0.005222 0.034223
3 446 0.079892 0.007833 0.042048
4 535 0.082471 0.010444 0.050438
5 621 0.084290 0.013055 0.058546
6 704 0.085690 0.015666 0.066371
7 779 0.086842 0.018277 0.073442
8 851 0.089970 0.020888 0.080230
9 951 0.123516 0.023499 0.089658
10 1097 0.193396 0.026110 0.103422
...
373 10482 0.998063 0.973890 0.988215
374 10502 0.998338 0.976501 0.990101
375 10522 0.998626 0.979112 0.991986
376 10541 0.998940 0.981723 0.993778
377 10560 0.999346 0.984334 0.995569
378 10578 0.999594 0.986945 0.997266
379 10586 0.999699 0.989556 0.998020
380 10598 0.999856 0.992167 0.999152
381 10607 1.000000 0.994778 1.000000
382 10607 1.000000 0.997389 1.000000
Всего страниц: 383
Всего слов: 76403
Всего уникальных слов: 10607
Прочитав 140 страниц книги (36.55% всей книги) вы узнаете 6585 уникальных слов.
К этой стрнице будут встречены 90% всех слов книги и 62.08% уникальных.
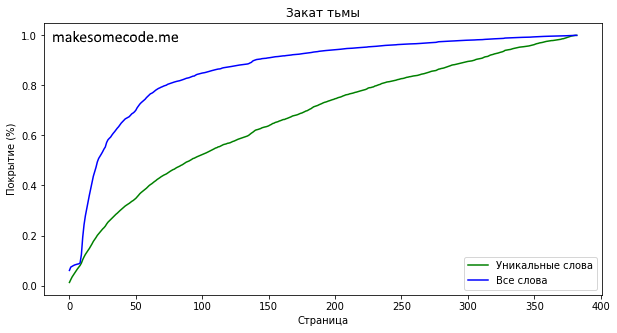
Книгу Тармашева “Закат Тьмы” решил взять как образец современной литературы (и потому, что она была бесплатной на litres). Книга среднего объёма - 383 страницы без стоп-слов. Уникальных слов 10607 и зная 6585 (можно встретить прочитав 140 страниц или 36.55% всей книги) можно прочитать 90% всей книги.
Ш. Стрэйд “Дикая”
dikaya_df = txt_to_pages('./books/Stryeyid_Sh._Proekttruesto._Dikaya_Opasnoe_Puteshestv.txt',
encoding='1251')
percentage(dikaya_df, 'Дикая')
page total percent of all percent of book uniqueness
0 156 0.083797 0.000000 0.014677
1 281 0.130858 0.003247 0.026437
2 421 0.157755 0.006494 0.039609
3 568 0.218298 0.009740 0.053439
4 711 0.269051 0.012987 0.066892
5 839 0.318194 0.016234 0.078935
6 948 0.352604 0.019481 0.089190
7 1052 0.372508 0.022727 0.098975
8 1158 0.407032 0.025974 0.108947
9 1258 0.430774 0.029221 0.118355
10 1342 0.448255 0.032468 0.126258
...
298 10423 0.996292 0.967532 0.980619
299 10430 0.996422 0.970779 0.981278
300 10456 0.996861 0.974026 0.983724
301 10469 0.997122 0.977273 0.984947
302 10484 0.997382 0.980519 0.986358
303 10515 0.997967 0.983766 0.989275
304 10603 0.999528 0.987013 0.997554
305 10629 1.000000 0.990260 1.000000
306 10629 1.000000 0.993506 1.000000
307 10629 1.000000 0.996753 1.000000
Всего страниц: 308
Всего слов: 61494
Всего уникальных слов: 10629
Прочитав 134 страниц книги (43.51% всей книги) вы узнаете 6997 уникальных слов.
К этой стрнице будут встречены 90% всех слов книги и 65.83% уникальных.
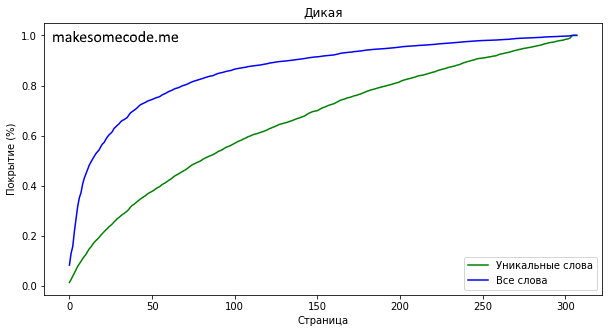
Ещё одна книга среднего размера - перевод книги Шерил Стрэйд “Дикая”. В книге 308 страниц со 10629 уникальными словами. Для того, чтобы прочитать 90% книги необходимо знать не менее 6997 уникальных слов. Этого можно добиться прочитав 134 первые страницы (43.51% всей книги).
А. Чехов “Человек в футляре”
man_in_the_case = txt_to_pages('./books/Chehov_A._Man_in_the_case.txt')
percentage(man_in_the_case, 'Человек в футляре')
page total percent of all percent of book uniqueness
0 169 0.266868 0.000000 0.153358
1 307 0.402820 0.100000 0.278584
2 426 0.507049 0.200000 0.386570
3 549 0.628902 0.300000 0.498185
4 652 0.717019 0.400000 0.591652
5 751 0.779960 0.500000 0.681488
6 858 0.854985 0.600000 0.778584
7 934 0.903323 0.700000 0.847550
8 1022 0.954683 0.800000 0.927405
9 1102 1.000000 0.900000 1.000000
Всего страниц: 10
Всего слов: 1986
Всего уникальных слов: 1102
Прочитав 7 страниц книги (70.00% всей книги) вы узнаете 934 уникальных слов.
К этой стрнице будут встречены 90% всех слов книги и 84.75% уникальных.
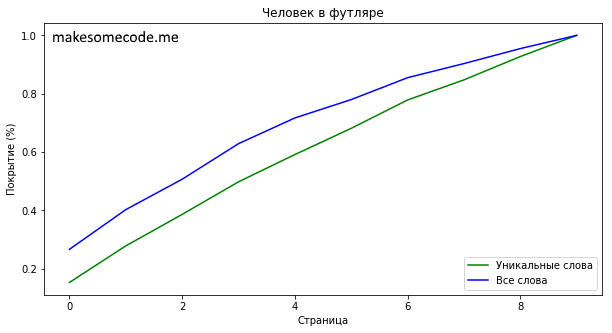
Последней книгой был короткий (всего 10 страниц) рассказ Антона Чехова “Человек в футляре”. Уникальных слов в книге немного - 1986. 90% книги написаны с использованием 934 уникальных слов (84.75% от всех уникальных слов), которые будете знать прочитав 7 страниц (но в это случае проще дочитать книгу, чем заниматься подобной ерундой, как подсчёт сложности книги).
Выводы
Во всех проанализированных книгах новые слова встречаются в течение всей книги (зелёная линия на графиках). Однако, если обратить внимание на синюю линию, то заметно, что б_о_льшую часть встречаемых слов в книге можно начать “понимать” довольно рано.
Возможно, это совпадение, но графики для художественной литературы (“Война и мир”, “Дикая”, “Закат Тьмы”) похожи. В это же время графики для книги “Маркетинг игр” идут значительно ближе друг к другу, т.е. книга “сложнее”.
Особняком стоит книга “Человек в футляре” Антона Чехова: она очень короткая и для того, чтобы встретить 90% уникальных слов потребуется прочитать всю книгу (см. таблицу).
На этом на сегодня всё.